
As cloud services mature, one of the trickiest problems is definitely data sprawl. Issues of rationalization and migration of data become a challenge as information spreads across multiple services. If you consider music as an example, it is definitely possible to end up with a collection that spans Amazon Music, Google Music and iTunes. One of the only real ways to keep those particular services synchronized is to source them from a common distribution point, preferably living on a pure storage service. Of course depending on the size of your collection, this can require a fairly significant investment in cloud. In recent months, though, there has been an incredible land grab for consumer business that has seem rates for storage drop dramatically. Currently, this is how my personal spend/GB looks:
| Base Storage for Subscription Tier | Extra Storage (bonus, referral, etc) | Monthly Cost | Note | |
| DropBox | 100GB | 7GB | $10 | |
| OneDrive | 1,020GB | 10GB | $11 | Office365 Home Sub – lots more than just storage in here – plus 20GB base storage |
| Google Drive | 100GB | 16GB | $2 | Includes Gmail and Google+ |
Pretty impressive! Tallying things up, we’re looking at a total spend of $23 which provides:
- 1253GB storage across 3 providers
- Office 365 access (mail, SharePoint, Office Web Applications)
- Office local install for Mac, PC, Android, IOS (multiple machines)
- Live Mail, GMail, Google Plus
- Desktop/device integration for all providers
To me this seemed like a fantastic deal for less than $25 a month and 1.24TB in the cloud is a ton of storage. As a result, over the past few months, I have been shifting to a cloud only model for data storage. The way I decided to run things was to make DropBox my primary storage service. Despite having by far the worst economics (ironically DropBox has become ridiculously expensive compared to the competition), it has the best client integration experience as a result (IMO) of the service maturity.
So with DropBox in prime the next challenge was figuring out a plan for the secondary services. At first I tried a model where I would assign use cases to each service. So music in Google only, pictures on OneDrive only, documents across all 3. This quickly fell apart as you wind up in a model where you need to selectively sync the secondary services, and you lose redundancy for some key use cases. In analyzing my total usage pattern though, I found that as a high watermark I consume 75GB of space in the cloud (including documents, photos and music). With the current $/GB rates, this data volume can easily fit in all 3 providers. Realizing this I quickly moved to a hub/spoke sync model where I utilize OneDrive and Google Drive for backup/redundancy and DropBox becomes the master. Of course the logistics of this proved very challenging having to utilize a middle man client to funnel the data around. There had to be a better way. Wasn’t this a great idea for a startup? Well… Enter CloudHQ!
CloudHQ aims to provide a solution of the monumental task of cloud data sync. As a premise it sounds amazing! Just register with these guys, add your services, create some pairings, and let their workflow (and pipes) do the rest. I’ve been tracking these guys for a while and it appears they are delivering. Of course the challenge is that to do meaningful work (more than one pairing) you need to pony up to the commercial level. I held off a while to see how their service would mature. Recently, though, they had a price drop that I feel represents a fantastic deal. I was able to get onboard with the Premium level subscription for $119 by committing to 1 year. $10 a month is just a terrific price for a service like this so hopefully this price will lock-in moving forward. Of course the service does have to work or it’s not such a great price right? Well let’s see how things went!
First off… The sign-up and setup process was fantastic. I actually went through the entire setup on an iPhone over lunch using my Google oID as a login. Once signed up you can jump right in and get started. Here is a shot of the basic mobile UI:
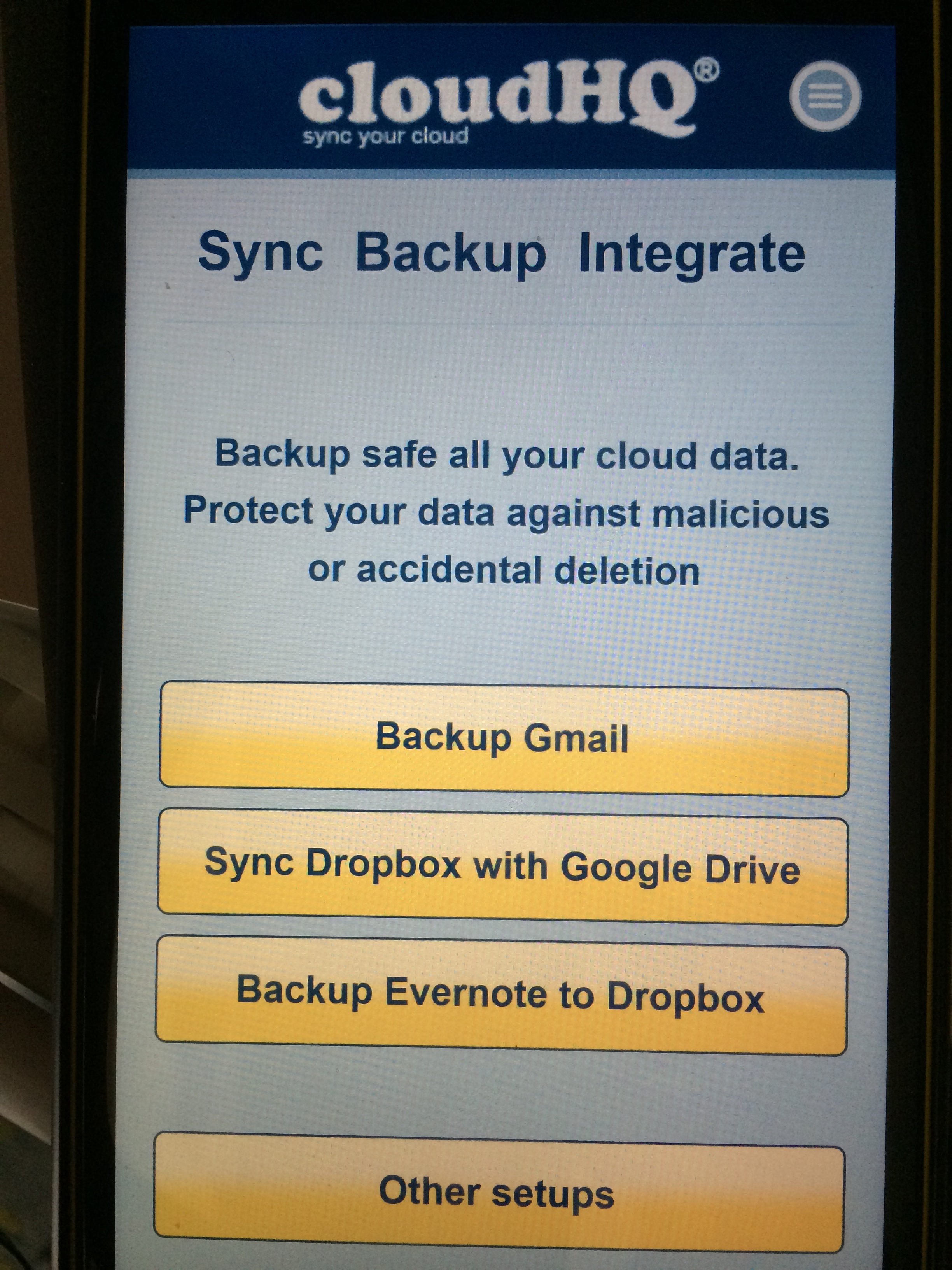
I love how clean this is. Very clear how you can get started creating sync pairs using the supported named services. Clicking one of those options will trigger a guided workflow. In addition, you can setup your own sync pairs manually. Either option brings you to service registration:
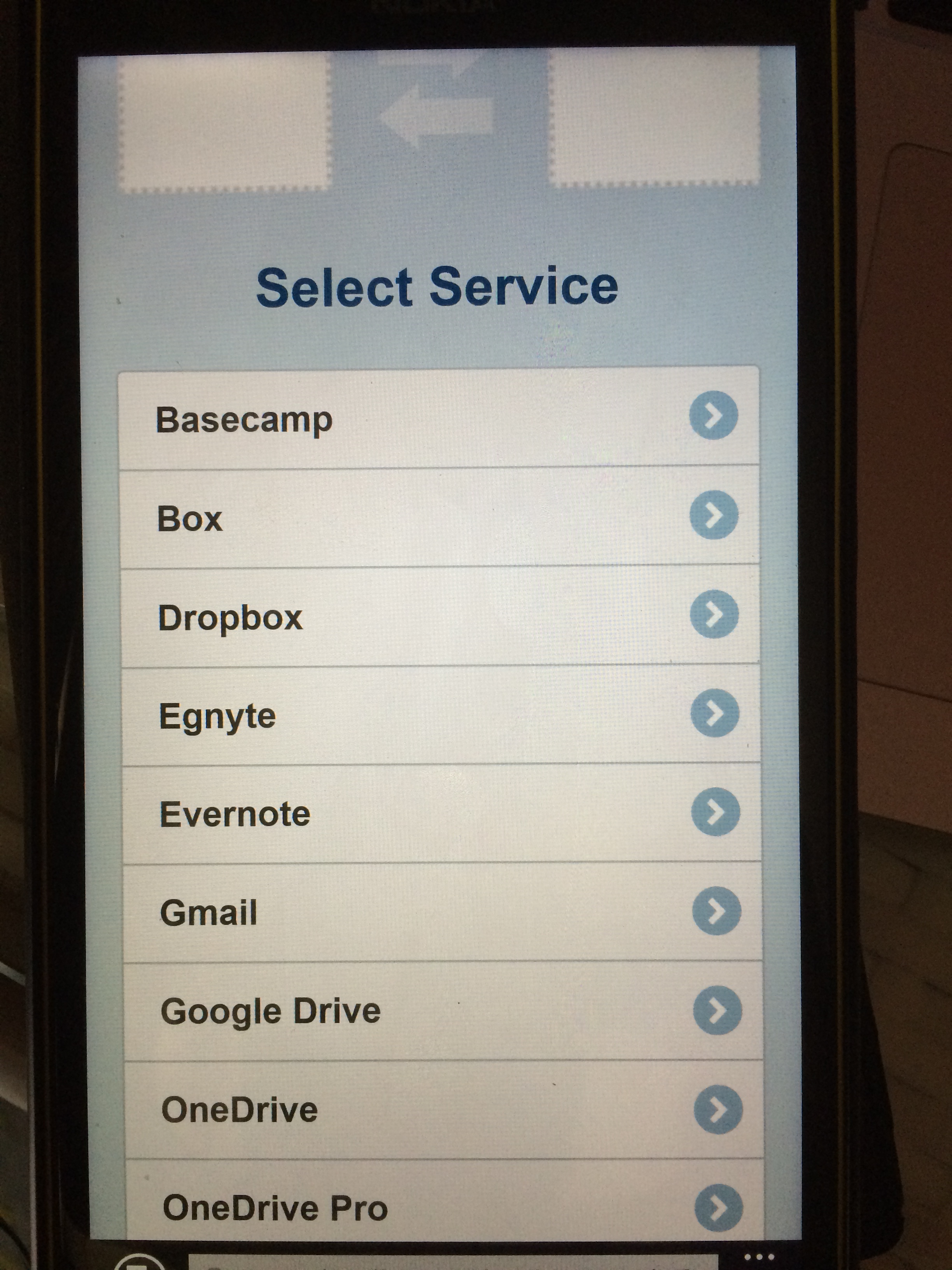
CloudHQ currently supports a very nice set of services. Supported services view from the desktop UI:

Once services are registered and sync pairs registered, the service will start to run in a lights out fashion. Updates are emailed daily and a final update message goes out once initial sync is completed. The stages break down as follows:
- Initial indexing and metadata population
- Service sync (bidirectional)
- Initial seeding complete
- Incremental sync process runs indefinitely
In my case, there was about 75GB of data or so in play. The biggest share was on DropBox and there was a stale copy of some of the DropBox data already sitting on both OneDrive and Google Drive. In addition, there was a batch of data on both OneDrive and Google Drive that did not exist on DropBox. The breakdown was roughly as follows:
- DropBox – 56GB or so of pictures, documents and video
- OneDrive – subset of DropBox content, roughly 5GB of picture data and 3GB of eBooks
- Google Drive – subset of DropBox content, roughly 12GB of music and 5GB of picture data
The picture data was largely duplicated. In approximate numbers, about 40GB had to flow in to OneDrive and Google Drive and about 15GB had to flow into DropBox. Keeping an eye on sync status in the UI is terrific:
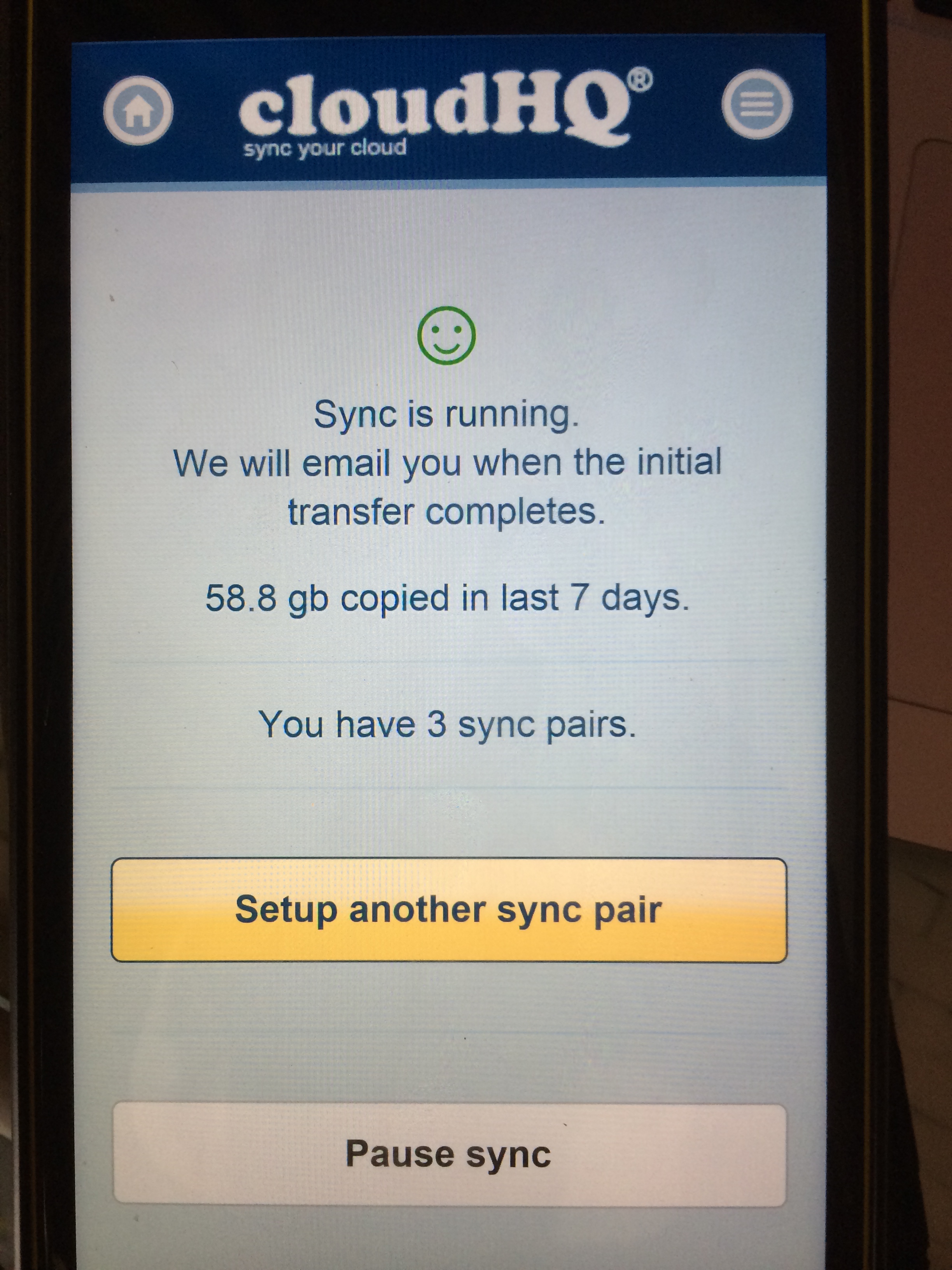
In the desktop UI, there is great detail:

The email updates are great. Here is a sample of the initial email:
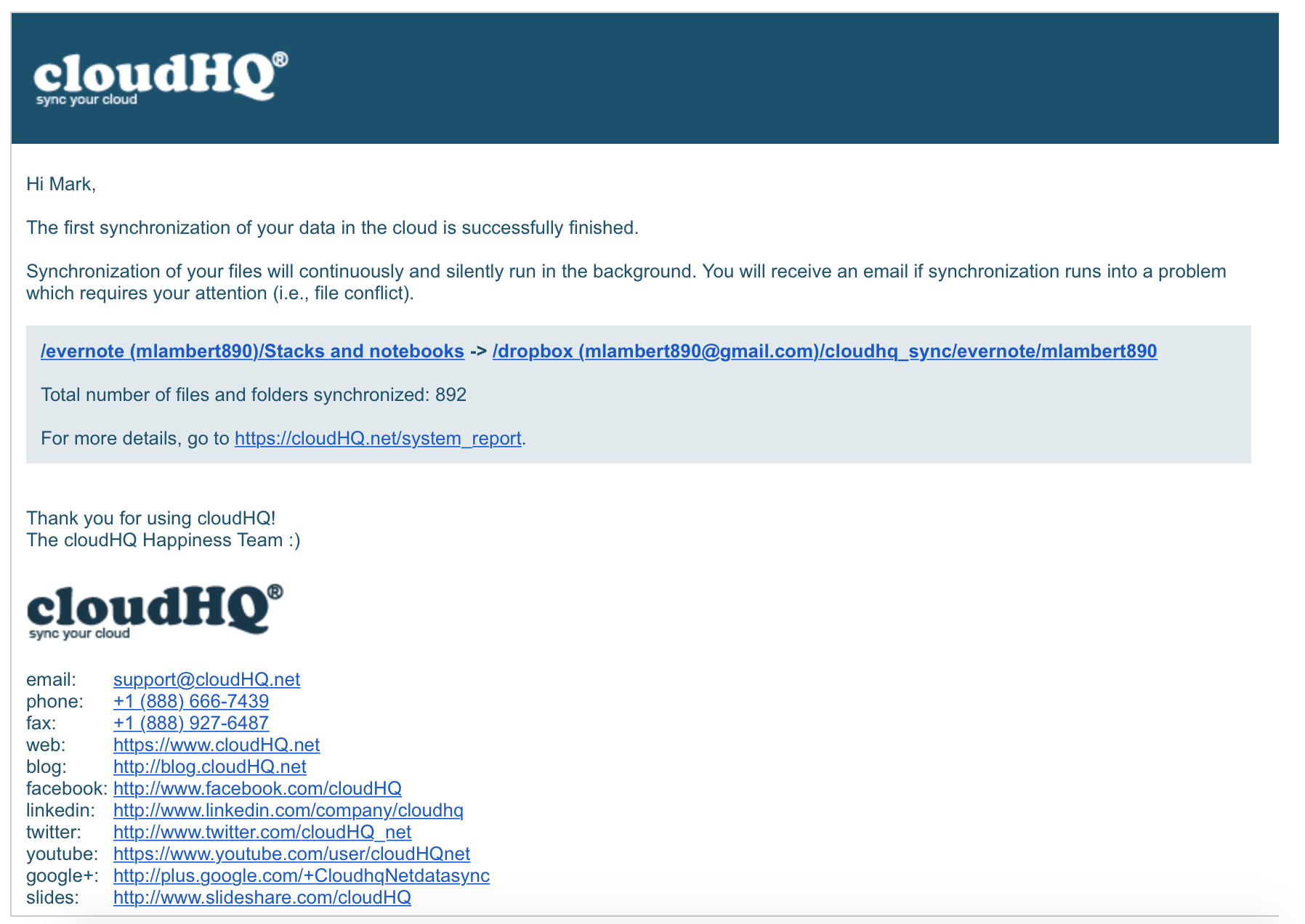
These updates are very straightforward and will come daily. The pair, and transfer activity for the pair, is represented. In addition, there is a weekly report which provides a rollup summary:
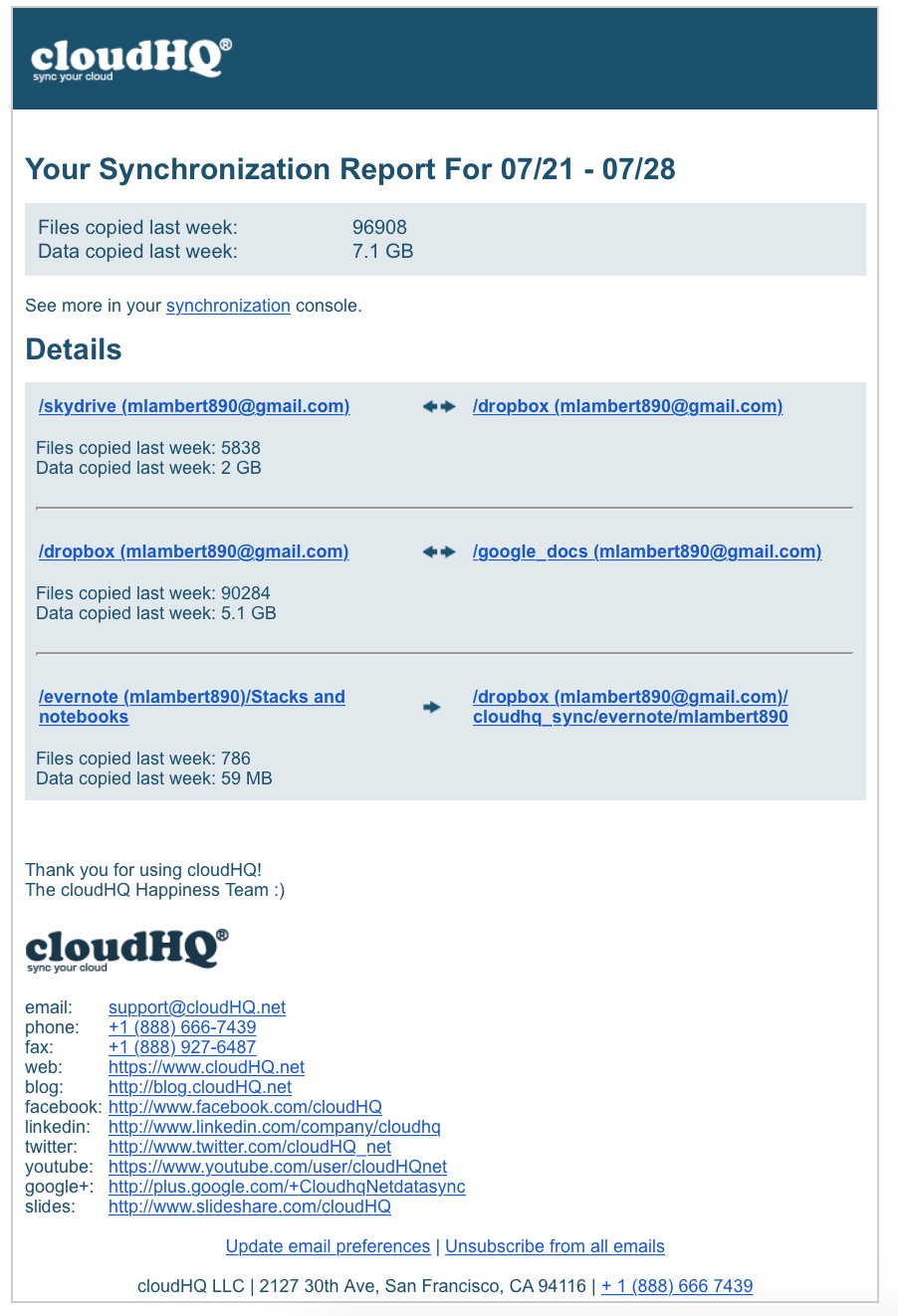
So how did the service do? Quite well actually. Here is my experience in terms of performance:
- Account Created, services registered, pairs added: 7/26 – 12:30PM
- Indexing and initial metadata population complete, Evernote backup complete: 7/26 – 9:52PM
- DropBox to GMail Complete, DropBox to OneDrive partial – 63GB copied: 7/29 – 10:30PM
No conflicts occurred and there have been no problems with any of the attached volumes. I have to say I am extremely impressed with CloudHQ so far and pushing 63GB of bits around in a matter of 3 days is a fantastic “time to sync state”.
As my experience with the service increases I will continue to post updates, so stay tuned!
