
Lot’s of noise lately about OpenStack and while I still feel the broader value proposition is limited (a subject for a different entry), as a service level architect on the provider side of the world, it certainly makes sense to get intimate with the technology at this stage. As is Android to mobile handset manufacturers, so has OpenStack become to “we need to build a cloud!” service providers. With HP, Dell, IBM and RackSpace on board (to name a few) it has become the collective answer for providers looking to compete against proprietary technology based offerings from AWS, Microsoft, VMware and Google.
So with this in mind, where do we begin? Well first, OpenStack of course is a “Cloud Computing OS”. What the heck does that mean though? Well in simple terms, OpenStack provides a centralized management system for advertising infrastructure services and resources to end users. These types of software solutions came about as an answer to the inherant multi-tenancy problem that IT providers run into as they try to rationalize the ever expanding supply and demand balancing act for resources into a service delivery model. Consider traditional IT approaches and it becomes clear why a new solution was needed.
Way back when in the early 2000s, all servers were physical computers that ran one instance of an operating system. Whether it be Linux, or Windows, or UNIX, the operating system provided developers and end users access to the processing and storage resources of the server. As an IT admin, if your developers needed to deploy a new application to support a business requirement, you generally found out somewhere in their development cycle that they would be needing equipment and, most likely too late, you would find out specifically how much equipment they would need. The equipment would then have to be procured through the normal (and extremely long) IT procurement process and eventually it would arrive and get deployed. By this point the developers would likely be dissatisfied that getting their equipment took “too long”.
Fast forward to the mid-2000s and along comes VMware and the breakthrough of production ready x86 server virtualization. At first this seemed miraculous and, although it took some time for most organizations to actually trust the technology for production and, even today, we are not 100% virtualized in the most mature markets, it ultimately did transform IT on some levels. After all, in the era of physical servers there was lots of wasted capacity. Moore’s law has been cranking along at full steam for a good long while now, but many business problems are still fairly simple. So each new application would require a new server from an implementation standpoint, but in reality the server was ultimately largely idle. This capacity management issue is where virtualization has had the most tangible benefit to date. Where complex resource management schemes put the burden of complexity on the developer (who often was not ready for it), virtualization presented exactly what they were expecting; a single server instance they could wholly consume. This ability to fully utilize big hardware by instantiating multiple copies of standard operating systems (Windows and Linux) really just scratches the surface, but was a big part of the initial value proposition.
Over time the “OS as code” approach of virtualization lead to more advanced management tools and the potential for more agile process. VMware in particular delivered next generation IT in the form of vCenter and near “magical” tools like vMotion. The logical presence of an OS was starting to decouple from its physical location giving high availability dependent design a new lease on life. Unfortunately, the broader potential inherent in this new model was never fully realized. The process aspects continued (and still continue) to lag. Lots of old physical process was dragged forward into the virtual world. Procuring a virtual server had similar approval gates as a physical one. In addition, most IT shops didn’t leverage virtualization as a starting point in turning themselves into a “broker of services”, charging for the resources they provide (despite the usage metrics needed to do this all being centralized in the hypervisor management tools). Lastly, the capacity management challenge still loomed, it had just been deferred. The “stair step” model of IT capacity boom/bust cycles remained with shortfalls in host capacity killing business agility and excess capacity on the shelf leading to deferred ROI.
In the past 6 years or so the situation for IT has gone critical with the gap between infrastructure teams and the business (represented by the developer community) growing wider. Analysts and developers have moved closer and closer to the core business in order to provide the agility required to compete in modern global markets, but core IT generally hasn’t followed along. Taken in this context, the rapid grass roots adoption of Amazon and it’s S3 and EC2 offerings becomes no real surprise. Much like RIM in the 90’s provided a solution to a problem IT didn’t realize it had (mobile worker productivity), Amazon found a ready, willing and indeed eager audience in developers frustrated by core IT’s inability to provide resources in time. These developers are under ever increasing pressure from their business partners to deliver solutions more and more quickly. Suddenly, with a credit card and a few clicks, they could have Windows and Linux servers online in 15 minutes. In addition, the entire service could be operated through an API (something core IT often can’t even spell).
Fast forward to present day and we find organizations in transformation. “Cloud” isn’t an “if”, it has become a “when and a how”. Every CIO worth the title has, at the very least, an articulated strategy for integrating cloud into their playbook (if for no other reason than pressure from the business). Naysayers and cynics persist (particularly within core IT), but my view is that we are seeing the creative destruction that we saw as centralized mainframe computing models shifted to the microcomputer distributed systems model. The naysayers will shift to a legacy and maintenance position and the sphere of control will shift. This is happening now and each day brings new developments. Developers, for their part, are also starting to shift focus to cloud design patterns. What this means is developing for “infrastructure as code” is following the approach that we see within agile startups (think Netflix and Instagram) even within the enterprise. Rather than assuming highly available infrastructure, you assume that your infrastructure will fail and you build your applications to not care.
So where does this leave core IT? Well the buzzwords today are “private cloud”, “hybrid cloud” and a host of others. What it really means though is that IT must evolve from being a builder of infrastructure to a broker of services. Classic virtualization management tools like vCenter and System Center Virtual Machine Manager remain focused on abstracting infrastructure (compute, network and storage) rather than on service creation. At the other end of the spectrum, complex management and orchestration platforms like those provided by BMC, CA, IBM or Cisco tend to provide a “lego set” approach where a wide range of legacy tools (configuration management, workflow orchestration, automation, etc) are rationalized together into something looking like a service controller, but never quite getting there. In addition, they are difficult to implement and operate, often requiring lots of customization (and consulting spend).
For its part, VMware took the curiosity that was Lab Manager (an attempt to build a multi-tenancy layer on top of the largely monolithic world-view of vCenter) and evolved it into vCloud Director. vCD was, in many ways, the first “Cloud OS” for builders. Of course vCD has an exclusively virtualized focus in general and VMware flavored virtualization in particular. It also remains somewhat incomplete if you consider building out a true infrastructure as a service offering. To remediate this gap VMware is shifting focus around as they evolve the entire vCloud Suite product line and is building a solid end-to-end story. Microsoft is doing similar work with System Center by way of the Azure pack and recently released IaaS extensions.
So what is it that all of these “Cloud OS” solutions (OpenStack, vCloud Suite, System Center IaaS, etc) are attempting to deliver? At a high level:
- Provide a Service Catalog facility – essentially the capability of building “recipes” (to steal a Chef term) or “blueprints” (to steal VMwares term) for advertising services. A “service” might be “Web Server” and come in “Linux/Apache” and “Windows/IIS” flavors. A “service” might also be “N Tier App” and provide options on the web, app and data tiers. Behind these service catalog entries would be provisioning logic to deploy and configure the required components once the service has been requested by an authorized user, which brings us to…
- Granular Role Based Access Control – RBAC is at the heart of all service delivery models. Most legacy management tools (System Center, vCenter) provide administrative access controls, but weren’t really designed to facilitate a self-service experience whereby there is an expectation that end-users will be able to directly request resources from the system. Because these platforms are mainly focused on infrastructure abstraction on the back-end, and were designed to be the foundation of a building rather than the entire 40 floors, this makes sense. RBAC is core to what the CloudOS brings.
- Configuration Management and Service Control – this is a tricky one. In some cases this is directly core to the mission of System Center and vCenter, but in many ways, for cloud scale, those tools don’t quite hit the mark. Capacity planning was a very rough exercise in traditional models with lots of “spreadsheet based” modeling. In a true dynamic infrastructure model, a centralized intelligence should be monitoring the total host footprint and proactively watch dogging capacity consumption rate and providing alerts on impending shortfalls. In addition, configuration of all base infrastructure (physical and virtual) should be centrally tracked (vCenter and System Center do this pretty well)
- Usage Tracking and Monetization – again an area where traditional management tools are too coarse. VMware offers (the now service provider only) vCenter Chargeback Manager and ITBM as great tools to help view virtual infrastructure through a service provider lens, but to provide real utility the Service Control layer must do granular tracking of resource consumption (metering of usage)
- Multi-Tenancy – this is the big one. For all of its power, vCenter still provides a “flat earth” view. Yes virtual machines can be grouped into “vApps”, and at the network and storage layers administrators can implement isolation, but ultimately a vCenter assumes that it is wholly owned by a single organization. There is no underlying facility to allow two different “virtual datacenters” (a logical collection of vCenter resources) to be isolated as if they belonged to entirely two different companies. In short, serving the infrastructure needs of Coke and Pepsi with one vCenter isn’t so feasible without a ton of abstraction. With vCloud Director (or any CloudOS) that higher level of abstraction, and the logical constructs required to enable it, are “in the box”.
- Resource Tiering and Dynamic Resource Management – an extension of the base infrastructure abstraction, a CloudOS brings another layer of orchestration providing increased agility. The need here is easiest to see from the network and storage perspective. Consider networking. In the multi-tenancy model, it is quite feasible to have 100 customers that all want “192.168.1.0/24”. Delivering this to them should not only be possible, but it should be automated and easy. In addition, the typical low-level network virtualization constructs like VLANs and VRFs are extremely limited in terms of scale and difficult to orchestrate (requiring scripted control of hardware devices). As a result, a modern CloudOS will leverage the more advanced virtual networking options inherent in modern hypervisors as a strong foundation. An example of this is VXLAN in vCenter/vCloud Director which allows for the dynamic provisioning of “virtual wires”, isolated layer 2 broadcast domains, which can be spanned across hosts over layer 3. Overlay networks unlocking previously impossible flexibility from layer 2 and layer 3 are a key part of the CloudOS value proposition. On the storage side, storage tiers become critical in terms of differentiating class of service. Whereas placement of virtual machines on volumes is proactive in a legacy model and determined by an administrator, in a cloud model it should be reactive and determined by end-user request and entitlement.
- Consumption Portal – ultimately the goal of a service broker IT model is to deliver a self-service consumption model to authorized end users. The synergy of all of the capabilities detailed above is realized in the customer facing portal through which an end-user can login, and based on their approval level (or willingness to pay on demand) start to provision and manage resources (servers, storage, etc).
If the above set provides a basic overview of the capabilities a CloudOS should provide, how many boxes does OpenStack check? Not surprisingly, it (roughly) checks them all. Unfortunately, in true open standards fashion, it puts multiple checks in each box. The flexibility and options are great, but it definitely steepens the learning curve, adds to implementation complexity, and fragments the ecosystem. Of course as with Linux distros there are a ton of OpenStack implementations. For the purposes of this experiment I chose to implement Mirantis. So let’s answer the above question from the perspective of the Mirantis solution:
- Service Catalog: check. Glance is the OpenStack component which provides the capability to discover and catalog instances (virtual machine templates and their meta data). Glance provides the foundation for the OpenStack catalog. As with all things OpenStack there are multiple options for the format of the VMs, the database which holds the catalog and the store which acts as the image repository. It’s worth stressing that the base unit for the catalog is literally a VM image (similar with the vCD catalog). If you are used to EC2, and the rich capabilities of CloudFormation or OpsWorks, the basic kit will come up short. The answer with vCD is to front end it with vCAC blueprints that offer far more complexity and actual workflow. With OpenStack, I suspect the answer is the same – front end it with a smarter tool. We’ll see how this goes later in the entry. Note that the actual catalog facility (vs the management of the entries in them) is provided by Keystone (detailed below under RBAC)
- Consumption Portal: check. Horizon dashboard serves as the consumption portal. For folks familiar with vCD, think of the vCD org admin view. As indicated above, it doesn’t provide the type of experience that you would get from a full consumption portal like vCloud Automation Center. This is a gap that can potentially be filled with third party integration (more complexity)
- Resource Tiering and Management: check. Quantum (network), Cinder (block store), Swift (object store) are the facilities which provide network and storage management (also worth mentioning is that the compute side is controlled by the Nova virtual machine management facility – more on this below). The network side is interesting. Quantum provides management and allocation of IP ranges to tenants, but it does not provide any controls for layer 2 (it is basically smart managed DHCP and IPTables). Neutron is the underlying virtual switch networking facility, but in vCenter integration scenarios it is only compatible with NSX and the plugin enabling integration can only be acquired directly from VMware. Without Neutron, Quantum allows customers to create and allocate networks and IP ranges, but it relies on VLAN isolation to be pre-configured accordingly in the vDS in order for traffic to flow (yikes – these are known as “Nova networks” and are directly defined in the environment config). On the storage side, Cinder provides block storage facility for Nova and provides storage tiering. Swift is the object store. For those who do not know, an object store is a storage system which is designed to overlay a highly scalable cluster of underlying storage nodes. The object store is accessed via a REST API and interaction with it is object level. So an API call is made, an “object” is passed (a stream of data), and this object is then stored distributed across the entire cluster. These storage facilities are designed for massive scale-out and high durability (think S3)
- Role Based Access Control: check. Keystone is the identity and access management facility in OpenStack and is also the actual service catalog. Keystone provides very good granularity for both administrative and end user roles, as well as SAML federation (all goodness)
- Configuration Management and Service Control: check. Nova, once again, is the facility which provides governance of virtual machine deployment and configuration as well as host configuration and capacity management. RabbitMQ and Puppet are under the covers and the entire workflow engine is front-ended by quite a good GUI called “Fuel” which we will be seeing in just a bit.
OK so that pretty much covers the key components of OpenStack! This is a good place to wrap this entry up. Next entry I will walk through actually setting it up. Before we go, a couple of pictures. First, a snapshot of OpenStack architecture component integration:

And one more (this one an original). We’ve talked a lot this entry about all sorts of components that make up this nebulous thing we call cloud. I’m a big believer in showing things in a picture, so technology implementation details aside, what does a “cloud service” really look like conceptually? Meaning, what are the capabilities that should underpin an efficient Infrastructure as a Service implementation? Here is my view:
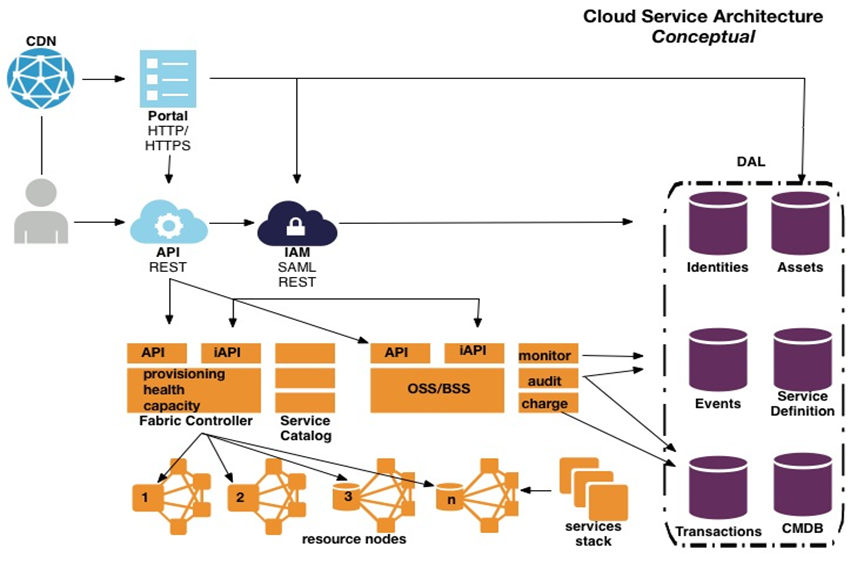
Most of what we see in the diagram has been detailed above, so the available frameworks on which one can build a service are getting closer to providing the right foundation for an ideal service. None are quite there yet, however, which is why the providers who can invest in proprietary glue code continue to enjoy a big advantage.
