
Even as enterprises just start to wrap their minds about how cloud in general will transform the way they operate, the goal post is already moving forward. If anyone out there has been looking for a final proof-point that the sphere of control has officially passed to the developer, this recent shift is all you need. What am I on about this time and what the heck does that title mean? A little history is probably in order.
In the beginning, there were Mainframes, and they were good. Developers wrote code and dropped it into a giant job engine which then charged them for the time it consumed. Paying too much? Well time to optimize your code or rethink your value proposition. This worked for quite a while, but as technology evolved it inevitably commoditized and miniaturized and as a result became far more available. Why wait in a queue for expensive processing time, purchased from a monopoly, when you could put it on your desk? The mini-computer revolution was here, quickly giving way to the microcomputer revolution, and it was also all good.
Computers stranded on desks aren’t particularly useful though, so technology provided an answer in the form of local area networks, which quickly evolved into wide area networks, which ultimately enabled the evolution of what we today call the Internet. All of these things were also good. As technology continued to commoditize, it became a commonplace consumer product like a car or a toaster. Emerging generations were growing up as reflexive users of technology, and their expectations were increasingly complex
To keep up, companies found they had to move fast. Faster than IT departments were able to. Keeping track of thousands of computers, and operating the big expensive datacenter facilities they lived in, was certainly an “easier said than done” proposition. By the mid 2000s, rapidly evolving agility in software came to the rescue of what was, in essence, a hardware management problem. Virtualization redefined what “computer” really means and operating systems became applications that could be deployed, removed and moved around far more easily than a physical box. This was also good, but in reality only bought IT departments a few years. The promise of virtualization was never fully exploited by most since the toughest challenge is almost always refining old process and , at the end of the day, there were still physical computers somewhere underneath all of that complex software.
In the last years of the last decade, a new concept called “cloud” grew out of multiple converging technologies and was the catalyst that literally blew the lid off of the IT pressure cooker. If you think about how technology is consumed and used in any business, you have folks who look after, translate and then solve business problems (business analysts, developers, and specialists) and then you have the folks who provide them with generic technical services to get their work done (security folks, operations and engineering folks and support professionals). By the time “cloud” arrived in a meaningful way, the gap between technology folks in the lines of business, and the technology folks in core IT, had grown to dangerous proportions. In short, the business lines were ready for new alternatives. From cloud providers they found the ability to buy resources in abstract chunks and focus primarily on building and running their applications.
This trend has transformed IT and we are in the midst of its impact. The thing is, though, that technology adoption cycles at the infrastructure layer (once reduced to glacial pace by the limits of core IT adoption abilities) will now rapidly accelerate. Developers are expecting them to since the promise of cloud is to bring them all of the efficiencies of emerging technology with none of the complexity.
This is why, barely 2 years into the shift to cloud design patterns and cloud service consumption and operation models, we are already seeing a shift to containers (and also “SDDC”, but that’s a topic for another day) What do these technologies mean to the new wave of IT folks though? Well first let’s take a look at what we’re actually dealing with. I will focus on two rival approaches. The first is Amazons “Elastic BeanStalk”, which is how AWS answers the “Platform as a Service” question, and the next is the traditional “Platform as a Service” approach, and more recently the “Containers as a Service” (for lack of a better term) approach being provided by Google and Microsoft. To kick things off, a quick diagram:
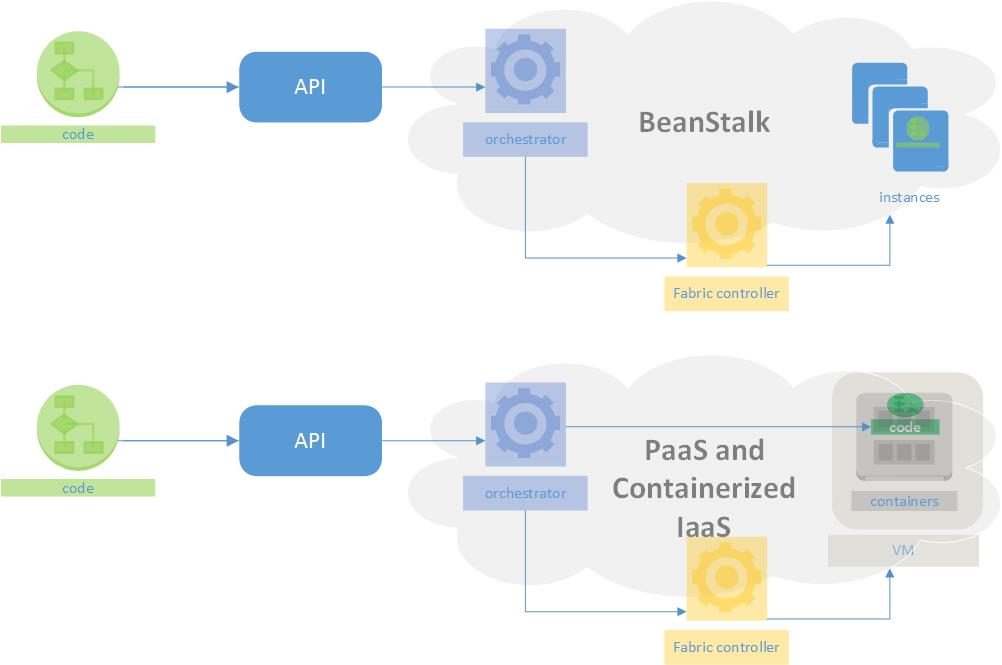 So what the heck is this about? A few quick definitions:
So what the heck is this about? A few quick definitions:
- Code – as implied, this represents a developer with a set of Ruby, Python, Java, or .NET code ready to be deployed onto some mix of compute, networking and storage
- API – in the world of cloud, where developers rule, the API reigns supreme. At code complete, developers will look for an API to interact with in order to deploy it
- Orchestrator – if YOU don’t have to care about pesky things like servers and disks, SOMEONE must right? Well that someone in this case is a smart piece of code called an orchestrator that will make some decisions about how to get your code running
- Fabric Controller – the true secret sauce of cloud. The brilliant code which allows mega providers to out-operate IT departments 1000 fold. Think of the fabric controller as the fully realized Utopian dream state of virtualization, and “software defined everything”. The fabric controller is able to manage a fleet of servers and disks and parcel their capacity out to customers in a secure, efficient, and highly available way that still turns a profit.
- Instance/VM – Amazon calls them instances, everyone else calls them Virtual Machines. It’s a regular operating system like Windows or Linux running on top of a hypervisor which in turn runs on top of a physical server (host) – OS as code. The fabric controller monitors, provisions, deprovisions and configures both the physical servers and the virtual servers that run on top of them.
- Container – the guest of honor here today. The ultimate evolution of technology that started with the old concept of “resource sharing and partitioning” back in the Sun Solaris days and continued with “application virtualization” like SoftGrid (today Microsoft App-V). The same way a hypervisor can isolate multiple versions of an operating system running together on one physical machine, a container controller can isolate multiple applications running together in one operating system. Put the two together and you have the potential for really good resource utilization
With the definitions out of the way, let’s take a look at how AWS does things with BeanStalk. Very simply, BeanStalk ingests the code that you upload and takes a look at the parameters (provided as metadata) that you have submitted with it. The magic happens in that metadata since it is what defines the rules of the road in terms of how you expect your application to operate. Lots of RAM, lots of CPU, not much RAM, more CPU than RAM… This is the sort of thing we’re talking about. The BeanStalk orchestrator then goes ahead and starts making provisioning requests to the fabric controller which then provisions EC2 resources (instances) accordingly and configures cool plumbing like autoscaling and elastic load balancers to allow the application to graceful scale up, and down, and function. Without caring about too much, you (as the developer), assuming your code works and you defined your parameters well, are in production and paying for resources consumed (hold onto that thought) immediately.
OK, that makes sense. It’s basically “autoprovision my infrastructure so I don’t have to think about it”. The developer dream of killing off their core IT counterparts. Microsoft explored the same concepts an age ago with the Dynamic System Initiative and the Software Definition Model ages ago and ultimately (sort of) evolved them into Azure. So how is PaaS different? And for that matter what the heck is “Containerized Infrastructure”?
Platform as a Service (PaaS), can be thought of as the final endgame. Ironically, we got their first. Google got the all rolling with AppEngine back in 2008. Microsoft actually lead with PaaS in cloud, a couple of years later in 2010, but for various reasons (a not so hot initial implementation, a customer segment that wasn’t ready, a hard tie-in at the time to .NET) they had to quickly backpedal a bit in order to get traction. In the meantime Amazon was piling on marketshare and mindshare year over year with pure Infrastructure as a Service (basically “pay as you go” virtual machines) and Storage as a Service plays.
What PaaS provides, ultimately, is something akin to the original Mainframe model. You push code into the platform, and it runs. It reports back on how many resources you’re consuming and charges you for them. Ideally it is the ultimately layer of abstraction where cumbersome constructs like virtual machine boundaries or where things are actually running are fully obfuscated. No PaaS really works quite that way though. What they really do is utilize a combination of containers and virtual machines. This brings us to today where “container solutions” like Docker are gaining lots of traction on premises and Google and Microsoft are both educating developers on being container aware in the cloud. Google has added the Docker compatible, Kubernetes based, “Container Engine” to their original “Compute Engine” IaaS offering and Microsoft has expanded their support for “Windows Server Containers” to include interoperability with Docker as well.
In the container model, a developer still submits code and metadata through an API, but what happens next diverges from what is happening in BeanStalk. The orchestrator has more options. In addition to asking for virtual machines from a fabric controller, it can also create a container on an existing virtual machine that has available resources. The way the virtual machines maximize resource utilization of a host, the containers maximize resource utilization of each virtual machine.
Now if you’re thinking to yourself “why should I care?” the congratulations! You get the cloud gold star of the day! I mean if we think about it, the point of cloud is that I really don’t care about what’s going on with infrastructure, so why should it matter to me how the provider is serving up the resources? Well there are two primary reasons:
- Economics – the whole point of this is doing more, and doing it more quickly, while spending less money. This is why cloud is unstoppable and CFOs love it. Despite protests to the contrary, it is proving cheaper than the legacy IT approach (no one is shocked by this except those with a legacy IT bias who have never deeply studied enterprise TCO). With BeanStalk, you have a fairly resource heavy approach. The atomic unit for scaling your app is a virtual machine. As your app grows, it needs to grow in instance based chunks and you will pay for that in instance hour charges. In theory a containerized back-end is more resource effective and should be more cost efficient. In reality this will vary widely by use case which brings us to the second point…
- Application Architecture – cloud design patterns are a fascinating turn around for development. Enterprise developers spent years, and technology providers built a plethora of technology and process, in order to create invulnerable platforms for code. Fault tolerance and high availability are industries because of this. Cloud basically throws all of that away. The mantra in cloud is “infrastructure is a disposable commodity” (this is the brilliant “Pets vs Cattle” analogy coined by Gavin McCance at CERN back in ’12) The idea in cloud design is to design for fail. You build resilience and statelessness into the application architecture and rely on smart orchestration to provide a consistent foundation even as individual components come and go. Containers are a natural extension of this concept, extending control down into each virtual machine. Container architectures can allow something like this:
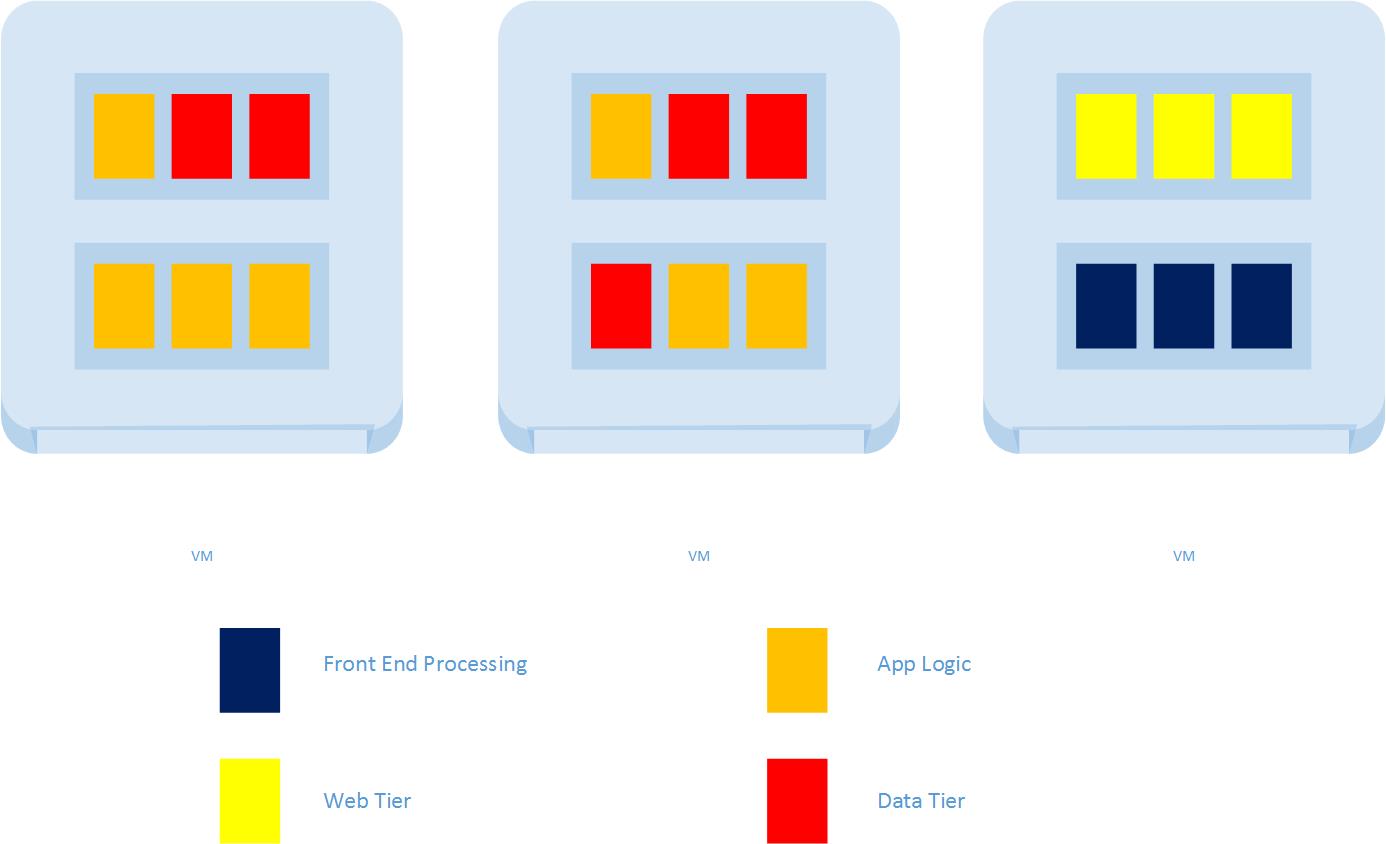
Obviously a hypothetical example, but a hint of what ultimately could be possible. If you think along the lines of app components being atomic units, rather than an OS, you can start to think about which components might benefit from co-location on a single machine. Intra-OS isolation can potentially allow scenarios that traditionally might have been impractical. So as you map out an architecture plan, you can begin to group application components by where they fit in the overall solution and allow the container orchestrator to group them accordingly. In the example above we have front end-processing co-mingling with the web tier while app logic code co-mingles with data. Again, this isn’t the best example, but it is definitely easy for illustration. Personally I think we are at the dawn of what can be accomplished with this next move forward. Now if enterprises can just catch up with the last one. They’d better hurry because, before you know it, containers direct on hypervisor will be here to really mix things up!
