
Don’t let the ridiculous, “stretches the definition to the breaking point”, acronym fool you, that’s just marketing after all, FREAK is serious business. For those not yet aware, FREAK is an exploit designed to take advantage of a critical vulnerability in SSL/TLS. For anyone who just said “uh oh”, that’s the spirit! Better grab a coffee. The “Factoring Attack on RSA Export Keys” (I know, I know… This doesn’t remotely spell “freak”. I told you the acronym was agonizing) is complex to implement, and requires a fairly sophisticated attack structure, but incredibly organized and sophisticated attackers are hardly in short supply in today’s threat environment. Before getting into how the exploit works. Some background is in order.
First is, of course, the “what” and “how” of SSL/TLS. Secure Socket Layer/Transport Layer Security, in a nutshell, are standard mechanisms for creating encrypted network connections between a client and a server. SSL and TLS take care of the encryption piece, agreeing on a method of how to encrypt the data (cypher), generating and exchanging keys, and then performing the actual encryption/decryption. Network transport depends on an encryption aware protocol like HTTPS or FTPS . Here is a nice detailed flow diagram that illustrates the conversation between the client and server (courtesy of IdenTrustSSL):
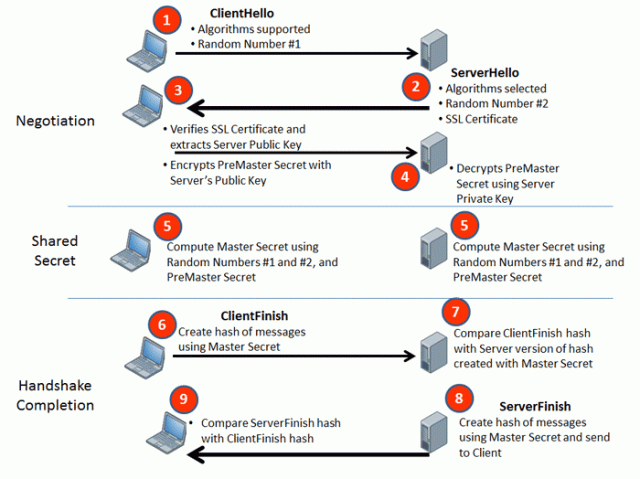
If you take a close look at the above flow, you’ll notice that there are really two encryption stages. Steps 1 – 3 are a standard PKI (Public Key Infrastructure) negotiation whereby a server is configured with a certificate (identifying it and providing authenticity assurance) and a public/private key pair. When a client comes and says “hello!” (plus a random number… more on that later), the server sends on over its certificate and public key (and another random number…more later). The client then decides to trust the certificate (or not and break the connection), and then sends over a new secret computed using the two random numbers we covered above, encrypted with the servers public key.
The server decrypts this with its private key, takes the secret generated by the client and, combing it again with the random numbers, generates a new key which will now be used to secure the channel for the duration of the connection.
Astute readers will notice that this means SSL and TLS are actually multi-layer encryption models utilizing both asymmetric encryption (separate public key and private key) for quick and easy implementation (nothing needs to be shared between a client and a server up front), and symmetric encryption (a single key for encryption and decryption that both sides know… A much faster method, but one which requires pre sharing). It is the best of both worlds. The channel setup efficiency and low level of required preconfigusation characteristic of asymmetric encryption plus the speed and added strength of symmetric.
In PKI methodology, the algorithm which generates keys should not allow factoring the private key from the public. To achieve a reasonable level of security, dual key systems require a very high key strength. Generally 1024 bits or greater. Symmetric key schemes can get away with much lower strength – 128 bit or 256 bit being reasonable. What does all of this mean? Well let’s take one more step back and just review quickly what encryption really is (diagram lifted from PGP docs):
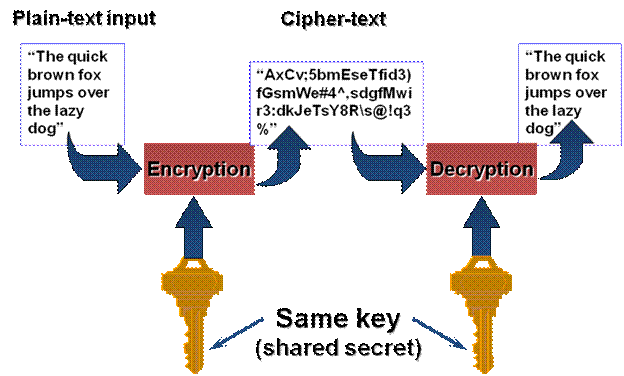
The above illustrates symmetric encryption, but the principal is always the same. There is a message that two parties want to share. They want it to be a secret so anyone who might intercept it or otherwise eavesdrop won’t understand. For time immemorial messages have been kept secret using codes. Encryption is a code. The message is put through some fancy math, using a big complex number as a constant (the key) and a scramble message is created. To descramble it, the message, the method (cipher) and the decryption key is needed. So when we say that symmetric relies on a 128 or 256 bit key, that’s the size of the numberical constant being used as a key (a big number). There is a lot (a LOT) more complexity here, but this is enough for the context of this entry.
Now obviously, there are many, many methods for actually encrypting data (the fancy math algorithm referenced above), and there are varying key strengths that can “work”. Typically it’s all a trade off between performance (compute overhead), which means cost, and security.
If the message does get seized, however that was accomplished, the data thief has a bunch of scrambled nonsense. But as with any code, it is possible to “brute force” decrypt the message. Basically try every possible value as a key. The catch is, with a large enough key, there just isn’t enough computing power available to try all of the combinations in a reasonable timeframe. At least there hasn’t been until now.
Enter… The cloud. I am a true believer when it comes to cloud. That said, I recognize than any great good can also be twisted to serve evil. In the case of cloud, nearly infinite compute capacity can be purchased on demand and paid for as an hourly commodity. It’s absolutely standard to day to model any computing task as a cost per hour directly mapped to a cloud service provider. And the resources can be provisioned programmatically. What this means is that brute force operations that would have taken a desktop PC 100 years, can now be carried out across 10,000 PCs in 10 days if you’re willing to spend the money. Still expensive, still not worth it. At least at 100 years. Of course with the proliferation of bot nets (or “dark cloud” as I like to call it), there may be no cost at all. But let’s leave that aside for now. What happens if the encryption is weak?
Enter… The export rules. Way back when the U.S. Government made it illegal to export strong encryption. Full stop. The US was, of course, also pretty much defining the technology the world was adopting. So what was considered “too strong”? Anything over a 56bit symmetric key system or a 512 but asymmetric. Egads! Over time this has strengthened (since it was ridiculous) and of course an admin could always simply force the strongest encryption (of course that would mean geographically load balancing traffic to keep non US clients outside of the US)
With this background in mind, what FREAK does is take advantage of a vulnerability in SSL/TLS (both client and server) which allows a bad packet to be injected into the up front client/server “hello!” exchange, selecting the weakest level of encryption. What this means is that, in the case of any servers which still have support enabled for the earliest “exportable” key strength (which turns out to be a LOT of servers), the key strength drops to 512bit.
Now combine this with cloud capacity (dark or legit) and you have about an 8 hour, $100, computing challenge to brute force a private key from a server since you now have a nice packet capture at 512 bit strength to take offline.
Wait! Take offline? Why would that work? Well. Here is the thing. The asymmetric key pair hangs around a long time. Sometimes like… Forever! Literally. Many servers only refactor on reboot and thanks to the miracles of high availability and “pets” based architecture approach (vs “cattle” in cloud design), that web front end may be online for years before rebooting.
So as you probably gathered, this requires a man in the middle:
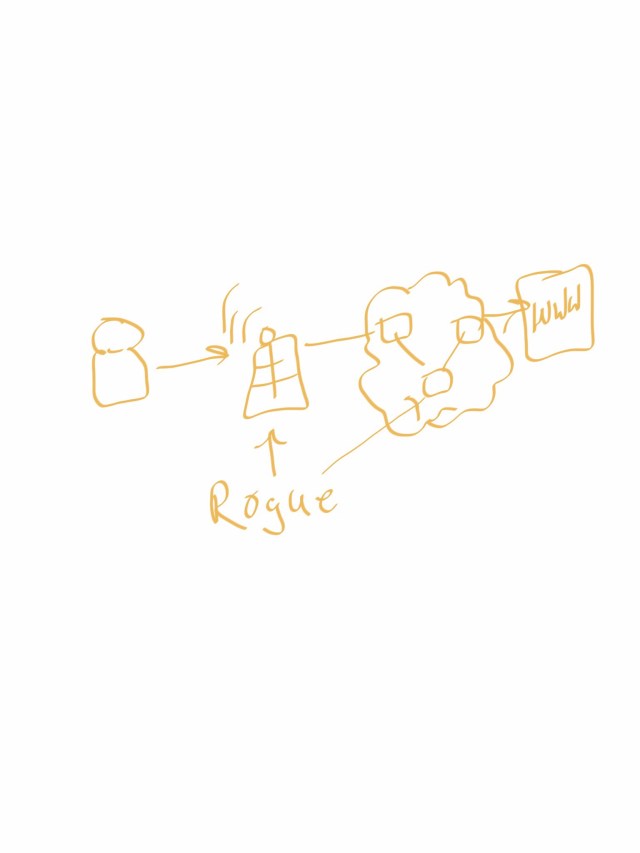
This can be as easy as a bad actor on public wifi, or as complex as a compromised ISP router in the path of a high value server. All very feasible to accomplish for a well funded black hat org.
Consider a real world potential scenario to imagine the possibilities… High value targets like Amex, Citibank and the FBI are vulnerable and have been for ten years (meaning export grade encryption is enabled and selectable). On the client side, nearly every platform is vulnerable! The last piece is that what used to be the hard part, compromising the network path, has become easy thanks to public wifi ubiquity. So let’s combine and imagine…
1) a popular public hotspot with weak security (WEP) and the key published on the register (or even not)
2) you hang out all day and capture wifi traffic
3) you either actually have the key, or you easily break it offline
4) with a nice unbound, shared media, network breached, you hang around and look for connections to the high value targets
5) you compromise the channel when you find one and start capturing weak encrypted traffic
6) traffic flow in hand, you brute force factor the key pair using about $100 of EC2 time
7) you are now free to watch and manipulate all traffic to the site until they change the key. Which may never happen.
So what are the implications if the exploit is pulled off? Well… The attacker has the private key. This means two big scary things:
1) until the keys are refactored they can instantly decrypt any traffic they can capture. Suddenly the expense of compromising an ISP path router just got a lot more realistic!
2) they can inject anything they want into an intercepted conversation
So do we turn off the interwebs??? Yes! Well no. But this is a big one and a ton of high profile sites are impacted. In my opinion a few things must happen:
1) weak encryption needs to be retired even as a configurable option. And export rules need to be gone. Strong encryption everywhere. Let the NSA build bigger brute force machines
2) servers need to be updated ASAP. Force strong encryption, disable export grade, and patch
3) keys need to be refactored multiple times per day. Yes this is computationally expensive. There are matter ways to do this than “bigger web server” though. Rearchitect. Design for fail. HSM. The truth is out there.
4) clients need to be patched as soon as patches are ready. Linux, OSX, Windows, IE, Chrome, Firefox, IOS, Android. Yikes!
Can anything be done in the meantime? Mainly be careful with public wifi (this is just a rule really). Stick with authenticated public wifi using stronger encryption or VPN. VPN is just a “from/to” secure channel to bridge networks, so it isn’t a panacea here, after all, you can’t VPN direct to a public server but it can help mitigate some risk exposure until the ecosystem is corrected.
Fun times!
