
There is no doubt that these are turbulent times for the poor downtrodden IT infrastructure pro. Most, having just barely gotten a handle on virtualization, are being bombarded by the commoditization pressure of public cloud, the consumerization pressure of BYOD and the increasinngly resource hungry and impatient call of developers, who are themselves under tremendous pressure to respond to the business with ever more agile, cost effective, yet differentiated solutions. As these trends converge what is becoming inevitable is that infrastructure, be it on prem or in the cloud, is transforming into code and devops models are emerging as the future of IT. You can see these trends represented directly in initiatives like “Software Defined Datacenter” and “Software Defined Network”. It makes sense as the evolutionary next step from virtualization, but most IT shops lack the maturity in management, orchestration and automation to make the transition without significant pain. In addition to the people and process hurdles, the technology still has some major gaps as well. Over the next few entries I plan to put down some of my thoughts around what I think the most significant barriers are, what can be done to deal with them today, and where the industry really needs to mature and invest. To start things off, I felt that networking was the best topic. If there is one area least prepared for this type of transformation, most intrinsically at odds with it really, it is the network.
I have no doubt that Software Defined Networks (SDN), are the future. A state where both control and data plane logic have been decoupled, separated, virtualized and collapsed into the compute tier and where location and identification have become discrete entities that can be managed independently. We have a long way to go however, before we are even near that utopian state in the traditional enterprise (public cloud vendors having had the benefit of building for scale from scratch and carrying no legacy baggage are much farther ahead). Before taking a look at where the industry is today, and where it should be headed, it is a good idea to review where it came from.
I said earlier that the network layer is the least prepared for dramatic transformation. To understand the reasoning behind this statement, one has to consider the basic foundation principals of computer networks. Of all computing subsystems, only the network strata truly concerns itself with physical location. The basic design of networks, from the smallest branch office to the largest datacenter backbone, centers on the mapping of computing resources to locations. Networks start with physical isolation and then build a logical topology based on it. Capacity is defined by hard limits like port density, bandwidth and physical cable lengths. A router is a device that, at its core, is traditionally relied upon to not move. The entire point of it is to not only be 100% available, but to help define availability for the devices behind it. Similarly, a network switch is literally hard wired into every device it hosts. And obviously there is really no escaping this at some level. Devices ultimately must connect to something and it helps an awful lot when you can find them. As distributed computing exploded, and networks grew exponentially, it became clear that scaling to tens of thousands of nodes presented a serious design challenge and technical bottleneck. Over time some abstraction technologies have developed, but at a glacially slow pace when compared to compute or storage. Examples are virtual local area networks (VLANs), allowing modern super dense switches that have lots of ports, processing power and backbone bandwidth, to carve their physical capacity up into multiple isolated networks. Originally tied into physical port groupings, things have improved over the years thanks to 802.1Q and that protocols ability to define VLANs using a system of logical labels or “tags”. This gives some flexibility to network designers who don’t have to predetermine how many actual physical ports a VLAN has to be up front. Now consider that 802.1q was only drafted in 2005! Other technologies have also emerged over the years to give network engineers some more flexibility. Routers can now maintain multiple routing tables using VRF (virtual routing and forwarding) allowing them to recognize and service potentially overlapping logical networks and many routing devices are also able to segment their own capacity into discrete virtual instances (examples are Virtual Device Contexts on big iron Cisco gear or virtualized firewalls in the Juniper product set)
All of these advances, however, have failed to keep pace with the rapid evolution in storage and the breakneck advancement in compute and virtualization. Today’s modern blade servers can easily put 200 modern multi Ghz highly IPC efficient cores and half a terabyte of RAM into a 6U chassis with 40+ Gb of shared Ethernet attach. Combine that kind of hardware with any modern hypervisor (be it ESXi, hyper-v or Xen) and you end up with, essentially, a datacenter in a chassis. With typical subscription ratios, and two such chassis in a rack, it is totally reasonable to plan for 1000 servers coming in through 8 physical network connections. Now consider that a huge part of the value proposition of virtualization is the ability to freely move those 1000 servers around to other hosts, and that the storage subsystems have made strides to increase how far away from each other those hosts need to be (including geographic metro distances with technologies like EMCs VPLEX which abstracts physical storage location essentially creating a virtual distributed array) and you can see how the network layer is becoming a real boat anchor on progress. Each of those servers essentially is its IP address. The IP address is its name, but its also its home address. It links it to a subnet which links it to a VLAN which links it to a router and a switch. Move it away and things get ugly. If it moves to a new neighborhood, courtesy of fancy virtualization technology at the compute and storage layers, no one will be able to find it unless it is given a new address. Nothing kills agility and automation more quickly then have to reconfigure a core OS setting as fundamental as an IP address!
So where do things stand today? Luckily even most large enterprises haven’t seen their maturity in virtualization and automation reach the point where these limitations have become a problem. Simply moving from physical to virtual has proven to be enough of a burden. The pressure of the economics and agility of the public cloud is making a massive impression on the business decision maker, however, and as discussed earlier, IT is in a position where a battle for survival is looming. If traditional infrastructure designs are “too hard” to provide the capabilities developers want around rapid provisioning and workload mobility, why not flush them? That’s the essence of the challenge facing IT.
Clearly it is in the best interest of vendors to push IT forward along the maturity curve and, in order to do that, building these massive architectures at scale needs to be made easier. Three technologies in particular represent attempts to address three different challenges brought by dense virtualized datacenter designs: Cisco OTV, VMware VXLAN and the LISP protocol. All of these are interesting and important to understand, none are “enough” or representative of what the future state will look like. With it’s Nicira acquisition, and the recent announcement of the NSX strategy (covered really well by Hatem Naguib of VMware here: http://blogs.vmware.com/console/2013/03/vmware-nsx-network-virtualization.html), VMware seems poised for some genuine disruption in this space, so that will be the one to watch. In the meantime, let’s look at the existing, currently available, technologies!
First up is Cisco OTV or Open Transport Virtualization (incidentally HP has a similar technology known as EVI or Ethernet Virtual Interconnect. The problem these technologies attempt to solve is the need to move IP addresses around over a large geographic area. By design, IP is all about segmenting a network into subnets. The idea was that datalink protocols like Ethernet were limited in their ability to scale, and that building big networks based on them required tying them together using bridges which allowed expansion but carried lots of complexity at scale. Datalink protocols basically see the world as flat. IP, and other network layer protocols, allow an administrator to segment a network into digestible chunks by applying logical address schemes. Considering this background, its rather ironic that virtual datalink topologies like OTV and EVI seek to improve the agility of IP networks by collapsing the bite sized chunks back into big flat spaces. What they actually do at a technical level is create a virtualized overlay network. What this means is that all of the Ethernet traffic originating from servers and clients, is encapsulated into GRE (a container protocol used for creating a tunnel through which network traffic can be sent) and then re-transmitted over IP. Consider this model (courtesy of Cisco):
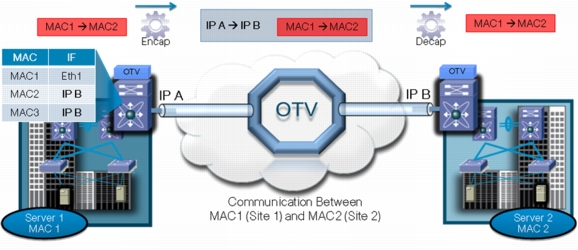
This is a really interesting concept and a creative usage of encapsulation. It provides primary layer 3 mobility by virtually, and transparently, extending layer 2 over an intermediary layer 3. Of course this does introduce some management and architectural complexity in that the new intermediate IP space used for encapsulation must be planned and managed, and performance must be watched pretty closely anytime you are dealing with encapsulation and de-encapsulation. In addition, there is a default gateway issue when workloads move as well. Looking at the model above, if server 1 were a virtualization host, and a guest from that host were to move to server 2 (also assumed to be a virtualization host), while the IP integrity would be preserved, there would be gateway inefficiency. In other words, assuming site 1 is still up, the guest (newly moved to server 2), would still be referencing the default gateway in site 1. Of course if site 1 were down HSRP, or another routing fault tolerance protocol, would rectify this, but a big part of the value proposition of virtual machine mobility is being able to distribute workloads geographically outside of disaster recovery scenarios. Luckily, another technology can be used in concert with OTV to help address this and that technology is the LISP protocol.
Locator and Identificatier Separation Protocol, as suggested by the name, is an attempt to decouple the concepts of IP address as both identifier and location specifier (your name and address so to speak). The mechanism by which it does this is by way of a another encapsulation scheme, in this case IP within IP, to create a true IP overlay mechanism. On top of the traditional routed IP topology, LISP overlays a new structure which LISP compatible devices understand and exploit. There are some key constructs to the new architecture:
- EID – the end point identifier. This is a LISP protocol definition for the end-point segment (host IP range)
- RLOC – the routing locator. “Non LISP space”, or the IP ranges assigned to the LISP participant routers and the addresses by which they exchange packets
- LISP Mapping System (MapDB) – the EID to RLOC mapping database by which the participant routers discover the location of end-point address space
LISP routers sit at the edge and are aware of their local IP space as well as their LISP tunnel address. If they receive traffic across the LISP tunnel interface that matches an address in their locally managed IP space (ingress), they de-encapsulate it and forward. Conversely if traffic originating in their local space matches a MapDB destination site (egress), they encapsulate the packet and route it accordingly to it’s correct RLOC destination. Because the mapping occurs on an IP host to RLOC level, hosts are free to move around. This facility of the LISP protocol is referred to as “dynamic EID space”. In other words, the end-point EID sets are free to transform dynamically. Vendor solutions can build on this functionality to provide full workload mobility solutions (example: Cisco VM-Mobility). So tying OTV and LISP together, how do the two combine and provide a synergy and how does it solve the gateway inefficiency problem? Because LISP is able to abstract location from identification, hosts which move across a defined dynamic EID range will have their egress traffic handled transparently by their local LISP end-point router. Consider the following diagram (again courtesy of Cisco):
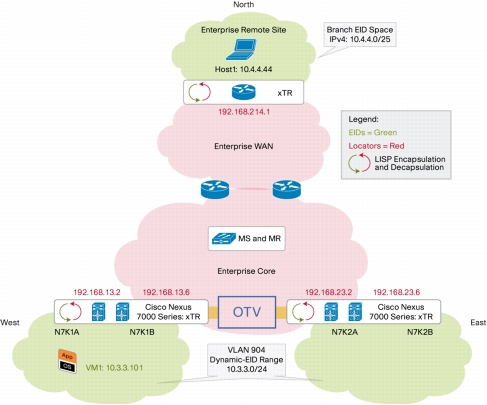
So it is pretty clear that OTV and LISP are somewhat complementary technologies and the two can be leveraged as the basis of some interesting, if complex, architectures. Where does VXLAN fit in? The short answer is that it really doesn’t. VXLAN is designed to address a very specific point problem: the inherent limitations of VLAN space, and their inherent lack of agility, due to the 12 bit addressing scheme and the fact that, by design, VLANs identify a block of physical network capacity. 12 bit addressing obviously translates into 4000 some odd unique VLAN definitions in a traditional implementation. This sounds like a lot, and in most cases it is, but when you consider dense multi-tenant virtualization scenarios, where dozens of different customers with dozens of required VLAN definitions, can reside on the same cluster and it starts to sound like not so much pretty quickly. As for agility, today VM placement for servers which have a very definite physical network mapping requirement (read most all of the legacy ones), really has to be governed by the availability of free network ports at the host network. In other words, if you have a set of VLANs, say 101, 102 and 103, and you have hosts whose physical network cards associate with these VLANs, the availability of those hosts determines where you can place things. If host 1 is on VLAN 101 and not 102 or 103, and I have a VM that needs to live in VLAN 1, then it needs to live on host 1; as simple as that. When you consider the complexities of scaling up VLAN distribution, this very quickly limits workload mobility and, as a result, host capacity management efficiency. To span these VLANs across these hosts traditionally, the layer 2 topology on which they live would need to be spanned. So if host 1 and host 2 are far far away from each other, and both need to be in the same VLAN, then they need to be in the same VLAN. The VLAN is owned by the TOR (top of rack) access switch. So host 1’s switch and host 2’s switch need to be trunked together. That’s where the “complex to scale” part comes in and this isn’t always a realistic option even within a datacenter, much less between them.
With the problem statement well defined and challenging, how does VXLAN seek to address it? Three guesses would probably be enough. With more encapsulation! Similar to it’s distant relative OTV, VXLAN seeks to extend the range and agility of layer 2 constructs by encapsulating layer 2 into layer 3. The main difference between the VXLAN approach, and the GRE based OTV one above, is that VLXAN occurs in software, in the vswitch, within the hypervisor. In addition, because the VLAN definition has now become a virtual construct, the sky is the limit on the number of definitions (well the limit is now 16 bit anyway, and 16 odd million!).
So how does the legacy physical switch infrastructure integrate with this new upstart virtual switch infrastructure that is pulling the rug out from under it? Well the news here is that it is a bit messy. This is the nature of the beast when integrating new concepts with legacy baggage. There are gateway devices that can connect the new fangled VXLAN virtual VLAN infrastructures with the traditional, physical TOR switch based, VLAN infrastructure. And as for the 12 bit physical VLAN definition limit? Well there is some segment:offset type magic here whereby the 16M becomes 4000×4000. Of course the management and all of this, and the tooling required to support it, is another issue altogether and one which should not be taken lightly! This is really necessary transformation though on the march towards the private/hybrid cloud models and if done right, really is liberating. Here is how VXLAN magic looks (this time courtesy of VMware):
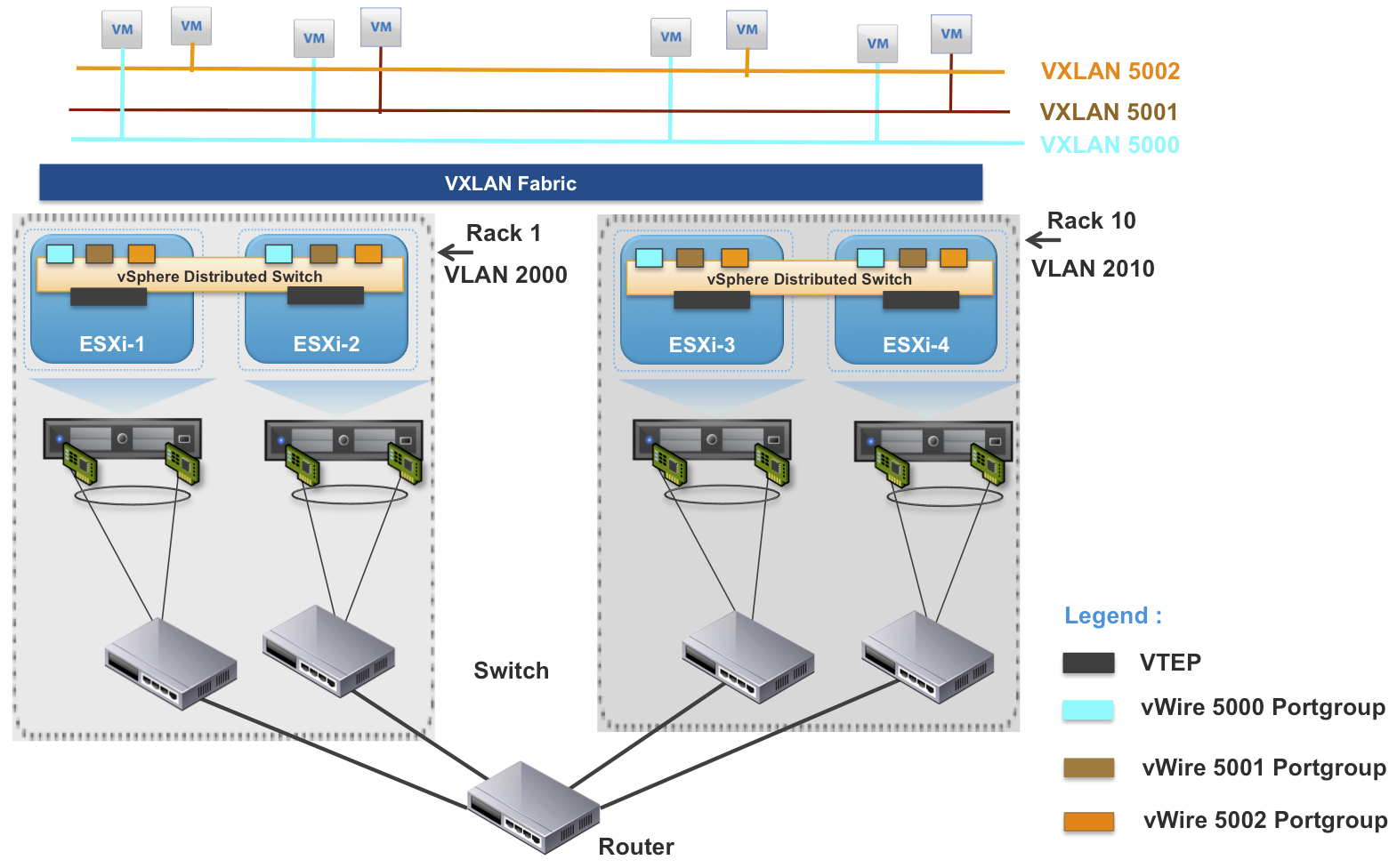
The interesting play here will be the emerging technologies. Particularly NSX. I think VMware is best poised to solve for this problem since their core competency is virtualization and they don’t have legacy bridges to burn (either product or tooling). Cisco has the deep networking expertise obviously, but how good of a thing the Software Defined Data Center ultimately would be for them is somewhat fuzzier and, at the very least, they have to bring forward a lot of baggage on the legacy support and tooling side. Without a doubt this will be a huge development space to watch!
