
Sometimes proper demystification requires a few passes. I received some questions about my last entry on vCD networking that got me thinking that for some, a slightly different view of the different components and how they interrelate might be valuable. I decided that a good companion to the last piece would be a deeper view of what’s going on at the vSphere switch and even physical switch levels along with some exposition on the why behind some of this architecture. I decided that the “VLAN Backed” network pool scenario is the most straightforward to use as an illustrative example, but I’ll touch just a bit on VXLAN, VCDNI and even just a tiny bit on OTV.
Before we take a deeper dive into the architecture introduced in the last entry, some background on the why aspect is in order. When considering the advanced architectures behind software defined network technologies, one has to keep in mind the fundamental problem space these engineering efforts are addressing. In short, virtualization, and in particular the “cloud service” flavor of virtualization, has really outgrown the constraints and capabilities of conventional network infrastructure. Basic switching and routing has served us pretty well for a long time without a doubt. The trusty OSI model, and the various link protocols operating at the datalink layer like ethernet, along with the various network and transport protocols operating at the network and transport layers like TCP/IP, have proven capable of reaching massive scale when well implemented as demonstrated by a little network we call the internet. Over the years, however, as requirements have outstripped capabilities, the IEEE has made iterative refinements to lots of these core protocols to make life easier. We’ve gone from the bus topologies of daisy chained network cards, to the inefficient star topologies of simple concentrators to the concentrator meets bridge approach of the modern ethernet switch. Each iteration has brought exponentially more performance and scaling potential. As port densities and backplane speeds have increased, networks have consolidated and management complexity has become increasingly important. In the early days to segment networks you installed physically separate switches. Two network segments meant two switches. Linking them meant connecting a router to each switch. As demand for better manageability increased we saw the introduction of the ability to partition a switch into separate networks by defining a new construct called a VLAN and assigning ports on the switch to it. This was terrific for a while until virtualization came along and made things more complicated. As discussed in the last entry, virtualization extends the physical ethernet switch infrastructure by layering a software virtual switch on top. Physically partitioning a switch port by port suddenly seemed cumbersome and it was clear that a more elegant solution, and a more logical one, would be required. To answer this demand the IEEE gave us 802.1Q and the concept of VLAN tagging. With VLAN tagging VLANs become logical identifiers that could simply be assigned to ports on the switch and groups of ports sharing the same identifier formed a logical network, adding the VLAN tag to each frame to keep traffic separated. This brings us up to just about yesterday and the advent of advanced overlay networking and the advent of Software Defined Networking.
So why is 802.1Q not enough? You can get a hint from the diagram above. As virtualization has proliferated, and as it has evolved into cloud service models, two big constraints of legacy networking have become limiting factors. Inside the enterprise, there is increasingly a need to extend host capabilities across lots of hosts across a widely distributed area in order to maximize service availability and provide a measure of disaster avoidance. If you are running 10 virtual machines (servers) on one host in one datacenter, you’ve actually just dramatically increased your risk exposure compared to the physical world. If you can distribute those virtual machines, however, across 5 hosts, and make those hosts highly redundant, you’ve just mitigated a chunk of that risk. This is super important as virtualization density has increased and those 10 servers have become 100 and 1000 on fewer and fewer hosts. Extending this logic, if you can then expand your pool of hosts across datacenters, you can potentially achieve a measure of disaster avoidance. The trick is, however, that this geographically distributed collection of physical resources must behave as one logical resource. As engineers began experimenting with these kinds of architectures, it became clear that current network technologies were creating a big barrier and primarily, the datalink layer. Ethernet is great, but layer 2 doesn’t scale well. It’s signaling is tied to physical limits like cable lengths and it’s addressing and announcement is based on broadcasts. VLANs do a great job of helping isolate ethernet networks into multiple broadcast domains to keep them at a manageable size, but VLANs themselves carry some tricky limits like their 12 bit address space (only 4096 VLANs defined in one common address space) and a VLAN itself is still a layer 2 construct.
Admittedly, most implementations haven’t hit these walls yet since most organizations are just getting to the point where they have mature virtualization footprints and are just starting to consider more advanced scenarios (things like geographic vMotion which require layer 2 to span multiple datacenters). Cloud, however, has been accelerating the push forward. Service providers already run into the big challenge of having to isolate lots of tenants, who each have their own network domains which must be kept separate, using existing technologies. All of the emerging advanced network virtualization technologies are designed to address these challenges and as a result, all of them are fairly similar.
vCDNI – the mission of vCloud Director Network Isolation was to provide tenant isolation in a vCloud. Since the whole point of vCloud is to make vSphere multi-tenant, and provide a foundation for both private cloud architects within IT, and public cloud architects at service providers to build on. The way vCDNI accomplishes this is by implementing a system of MAC in MAC encapsulation. What this means is that a new network identifier (known as a “fence ID” in vCDNI terminology) is defined and assigned to each tenant network alleviating the need to isolate tenants using VLANs. Since a vCloud Director implementation can (and will) span multiple hosts, and these hosts by definition must connect through a real physical network, a transport VLAN is identified on the physical NIC and is used for inter-host communication of vCDNI encapsulated traffic. A hypervisor kernel module on each host handles the duty of adding and stripping the fence-id to the frames as they are passed, and adding the VLAN tag when traffic must be passed through the physical link to another host. Within the vSphere Distributed Switch, vCDNI networks are provided by private VLANs.
VXLAN – the mission of VXLAN, as has been mentioned in these pages before, is to allow a virtual distributed switch to cover a much larger area than a typical layer 2 broadcast domain. It does this by way of MAC in UDP encapsulation. So where vCDNI does layer 2 in layer 2, VXLAN does layer 2 in layer 3. The way this works is that multiple virtual distributed switches participate in the VXLAN and traffic passes between them by way of a dedicated VLAN and IP subnet. If traffic must pass from a vDS on one participating host, to a vDS on another participating host, it is encapsulated in the UDP packet and sent across the physical network to wherever that host is (anywhere L3 accessible at this point – so latency and throughput become the only factors). In vCloud Director implementations where VXLAN backed network pools are used, tenant networks are assigned VXLAN virtual wires (logical network isolation provider – like a VLAN) Consider the diagram below:
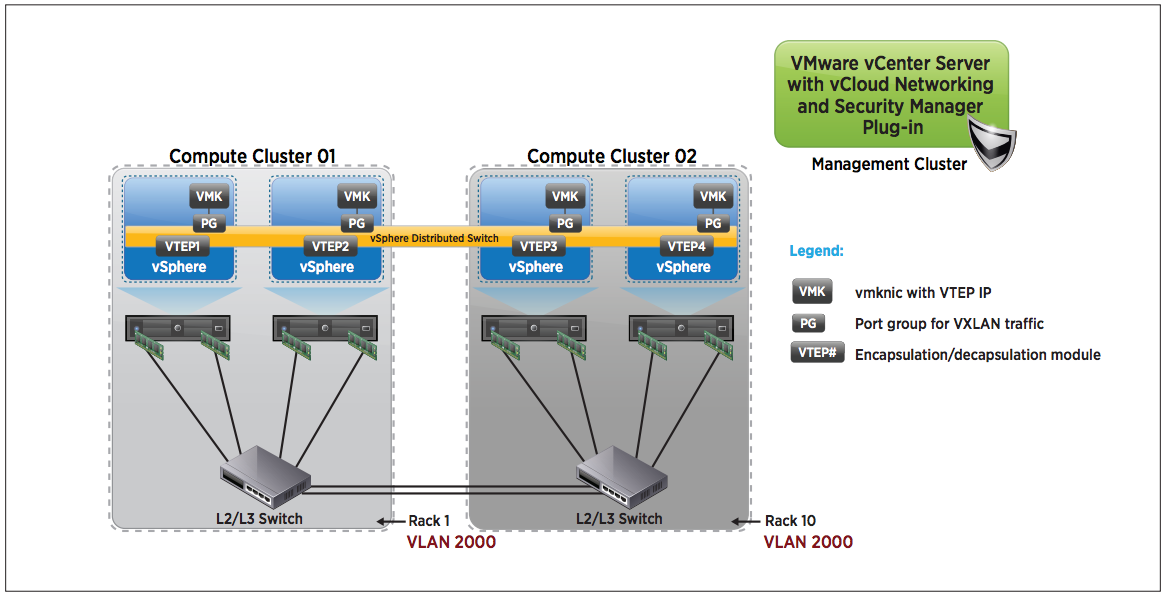
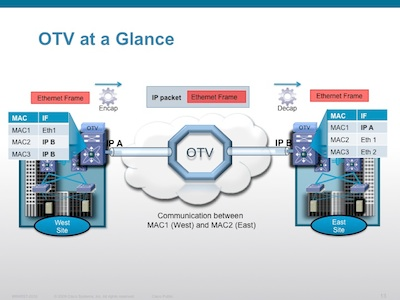
OTV – Ciscos Open Transport Virtualization is pretty similar to VXLAN in it’s mission statement and its general architectural approach, and super different in terms of it’s implementation. The idea is the same – take an existing layer 2 domain (ethernet segment) and extend it across a wide area using a variety of different transport options (including layer 3 via IP) in essence creating an overlay network. OTV is extremely cool because it does some clever things to really enhance the agility of layer 2. One of the most important is that it shifts the business of layer 2 reachability determination from the dataplane (where layer 2 protocols normally live), to a control plane protocol (where routing table assembly happens in L3 protocols) The one huge area where the mission of OTV diverges from VXLAN is that OTV is meant to be end point agnostic and be an enhancement to the core network infrastructure that works transparently to the hosts that utilize it. VXLAN, conversely, is deeply embedded in the fabric of specifically vSphere hosts as an extension of the logical virtualization architecture. It doesn’t concern itself with transforming the physical network architecture, but rather enhancing the virtual one. Ironically, however, OTV doesn’t specifically address VLAN id proliferation by introducing a new isolation construct, which VXLAN does do. Interesting times! In the interest of fairness, a quick OTV picture:
So by way of review, so far we’ve learned that while ethernet is cool, its limitations are increasingly a problem in a cloud focused world where you need to create and deploy lots of VLANs and want maximum freedom from worrying about where things physically live when planning topologies. The advent of some of these new, and sometimes confusing, technologies is a direct response to these needs and you see them featured so prominently in a product like vCloud Director because the business of creating and managing multi-tenant clouds is right at the center of where the needs arise.
With this background in mind, let’s take a new look at our vCD architecture:
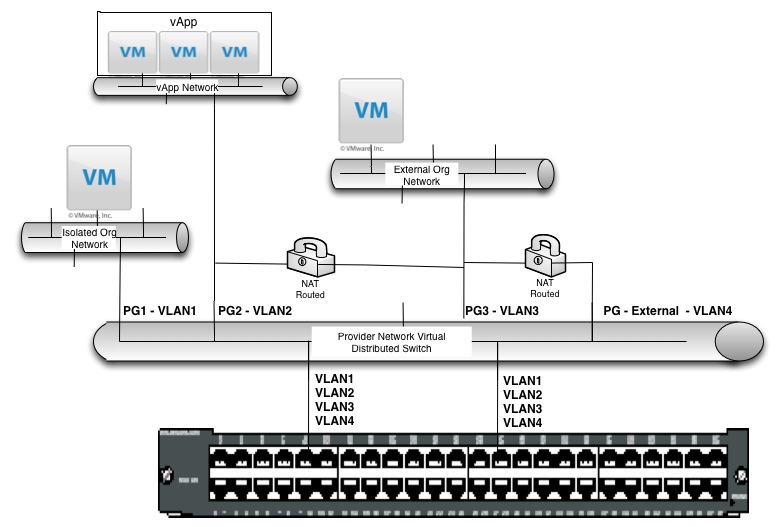
Well things are looking just a bit different now! As you can see, I have added the physical switch view, and have also attempted to diagram the actual interaction between vCloud Director Networking elements and the underlying vSphere virtual distributed switch. Here is a rundown of the changes and what they mean:
vApp Network – the big one here is that the vApp network is now shown as being connected to a port group all it’s own with it’s own VLAN id. Remember, for this example we are focusing on VLAN packed network pools. I chose these because they are easy to understand. Within the vCloud, anytime a new network is requested from a VLAN backed network pool, a new port group is created on the vDS and a VLAN is assigned to it from the pool. This happens anytime a new network is requested – that means organization or vapp, isolated or routed. The only exception is direct since obviously direct networks connect directly to the underlying network being referenced thereby sharing their port group (and extending layer 2). So you can see now that the vApp network, and its parent Org network, each have their own VLAN and port group, and the relation between them is created by the vShield Edge that provides the NAT/routed connection between vApp and Org. This is how things actually work under the covers.
Physical Switch – as you can see, our virtual distributed switch above has two connections to a physical switch. This can be two connections from one host or it can be twenty connections from ten hosts, the structure would be the same. What is important to note is that every VLAN id must be trunked to the uplink ports (connections to the physical switch). This is because the vCloud spans physical hosts, and the logical structures span those physical hosts, and organizational network or vapp network data must be exchanged between the participating hosts through the physical LAN. Therefore the physical switch must be aware of all defined VLANs within the vCloud Network Pools. When you consider this, and imagine big scale, you can immediately start to see the benefits of VXLAN, or vCDNI, which isolate tenant networks without consuming VLANs (using their own isolation identifiers) and consume just one VLAN for transport (in the case of vCDNI), or ride an existing VLAN/IP subnet (or newly dedicated one), in the case of VXLAN.
Hopefully this additional background and newly expanded diagram will help shed some additional light on some of the deeper workings of vCloud Director network as well as the rationale behind the current moves towards Software Defined Networks and reworking of legacy networking topologies!
